
How to Dynamically Create Triggers in Azure Synapse Pipelines



Triggers in Synapse pipelines determine when a particular pipeline(s) should be run. In an Azure Synapse environment, pipeline runs are typically instantiated by passing arguments to parameters that you define in the pipeline. You can execute a pipeline either manually or by using a trigger in a JSON definition.
Typically, triggers are manually created when needed. This can be cumbersome if you need to define and maintain many triggers, or if the duration or configuration of those triggers changes unpredictably. Setting up an automated process to create triggers can alleviate much of this manual work.
For example, let’s say that you need to trigger an Extract Load Transform (ELT) pipeline multiple times in a week, however, the time of day or number of times a week changes based on customers’ needs. Having to maintain a schedule to accommodate these varying needs is time-consuming, particularly if you have strict processes regarding approval for changes to production settings.
Let’s look at how to use the tools within Azure Synapse (data lake, key vault, SQL serverless database) to automate this process.
Scenario:
- Two customers defined as having a unique ExtractType code (A1 and B2)
- Creation of a single Synapse pipeline that will be triggered for either of these ExtractType codes
- All triggers will be defined as weekly recurring schedule-based triggers
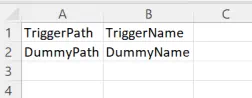
- The definitions of the triggers for both customers will be held in a single Comma Separated Value (CSV) formatted file

Create Example Data
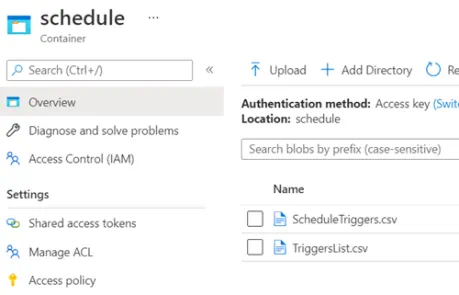
We start by creating a CSV file called ScheduleTriggers.csv that defines the day and time of the week a pipeline needs to execute for each ExtractType Code. This assumes a maximum of 7 executions per week but can be extended if needed. The file is then uploaded to the Data Lake.

We then create a CSV file TriggersList.csv, which will be updated by a Synapse pipeline to store all the current triggers existing on the Synapse workspace. We may need to remove any redundant triggers for an ExtractType code, and we may also have triggers that exist for other purposes. Therefore, we need to identify which triggers currently exist and which of those need to be removed specifically for our ExtractType code. We first create the file with dummy values and upload it to the data lake.
Set Up Database Environment
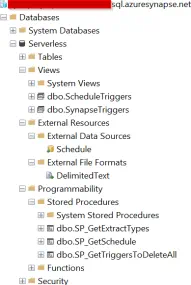
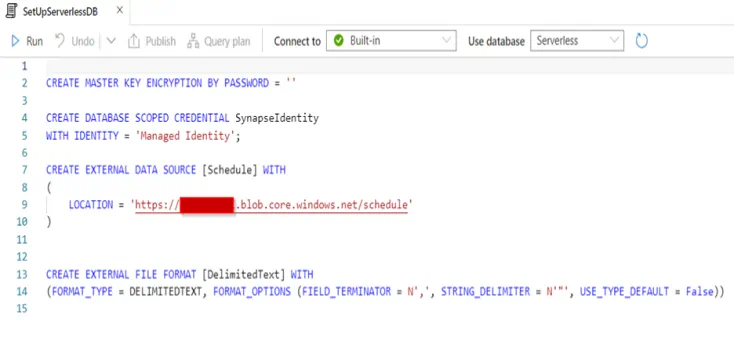
Next, we create and configure our Synapse Serverless database that will read the ScheduleTriggers and TriggerList CSV files we created earlier, straight from the data lake via SQL views.
The below SQL view is used to read the ScheduleTriggers.csv file and return the data in SQL table format.
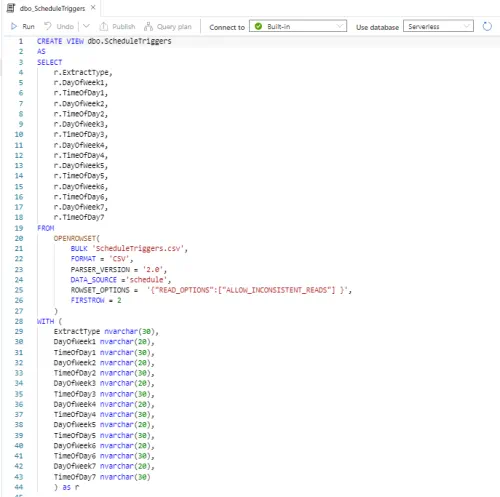

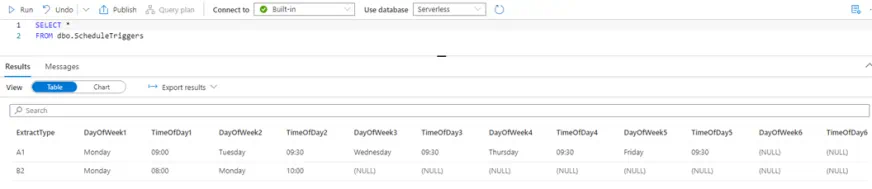
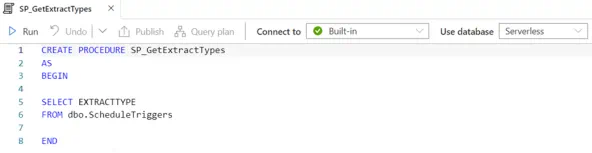
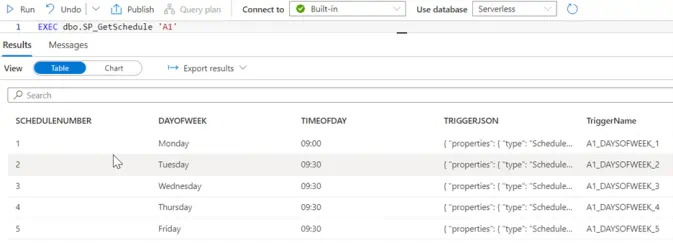
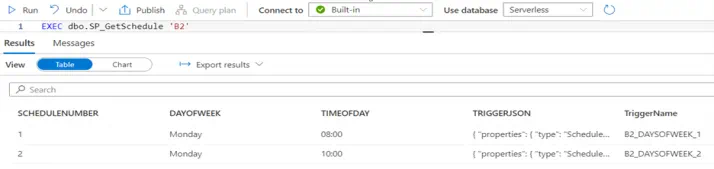
The following SQL stored procedure will be used by a Synapse pipeline to retrieve a unique list of ExtractType codes that we loop through and create triggers for.
The following SQL view is used to retrieve data in the TriggerList.csv from the data lake, which holds the current list of triggers existing on the Synapse workspace environment.

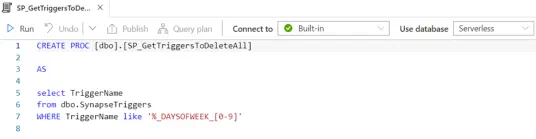
The following SQL stored procedure is used to read the previously mentioned SQL view and determine which triggers we need to delete and action this command via a call to the Synapse REST API.
The following SQL stored procedure is used to dynamically generate the JSON trigger definition that will be used to create our triggers, it uses the data retrieved from the dbo.ScheduleTriggers SQL view.
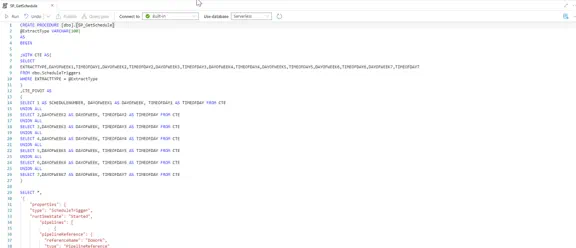
Create Synapse Pipelines
Now we have the underlying SQL code that will read our data Lake and generate the data set containing the definition of each of the Synapse Triggers we need to create. Next, we need to create the Synapse pipelines that will orchestrate the flow of logic to:
- Stop and delete all existing ExtractType triggers on the Synapse workspace
- Retrieve the list of ExtractType codes to iterate over and call the SQL stored procedures to get the list of triggers to create
- Create each trigger
- Start each trigger
First, we will create a simple Synapse pipeline called DoWork. The pipeline will expect a parameter called ExtractType to be passed when called and it will simply execute a Wait task for one second.
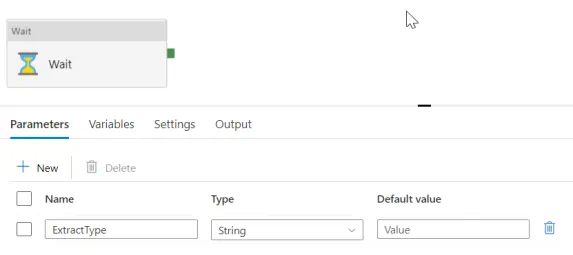
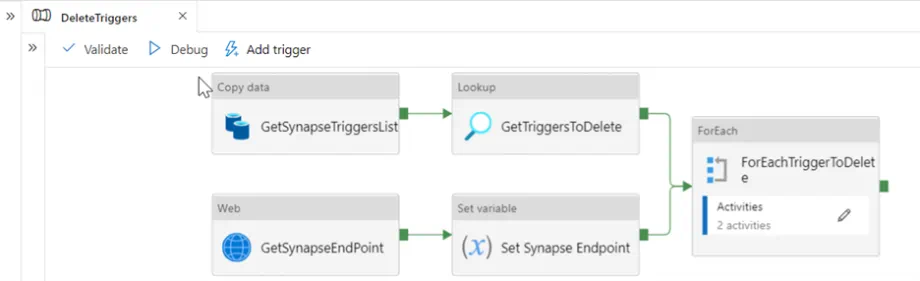
Next, we create a Synapse pipeline called DeleteTriggers that will retrieve the list of triggers from the TriggersList Data Lake file and make a web request call to the Key Vault to retrieve our Synapse workspace URL endpoint. The endpoint is stored inside of Key Vault Secret, so that we can make web request calls to the Synapse REST API to first stop and then delete each trigger.

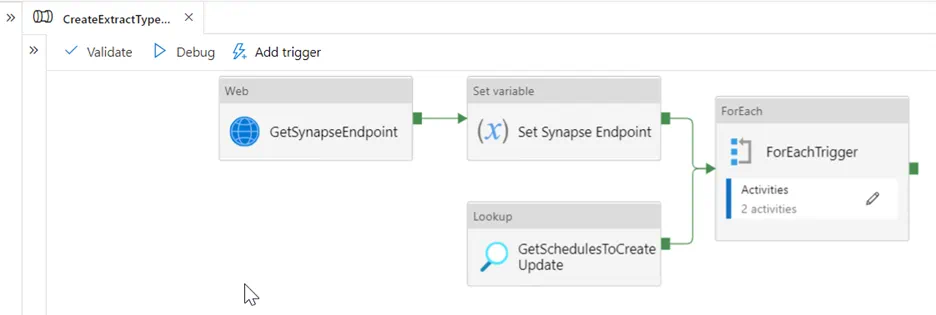
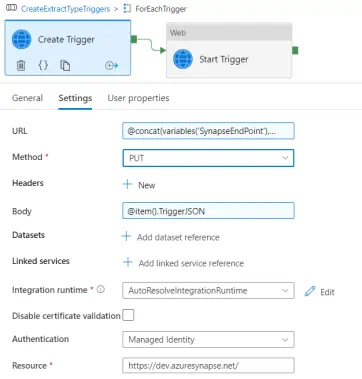
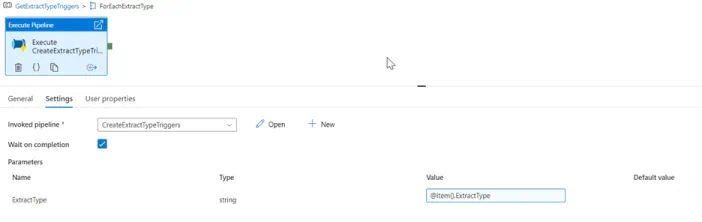
We then create a Synapse pipeline called CreateExtractTypeTriggers that calls our SQL stored procedure dbo.SP_GetSchedule to retrieve the list of triggers to create and the JSON definitions by passing in a pipeline parameter called ExtractType. Once we have that list of triggers as an output, we can iterate over each row from the output and make a web request call to the Synapse REST API to create and start the trigger on the Synapse workspace. We again retrieve the Synapse workspace Endpoint URL from our Key Vault and send the trigger JSON definition created from our SQL stored procedure as part of the body of the web request to the Synapse REST API.
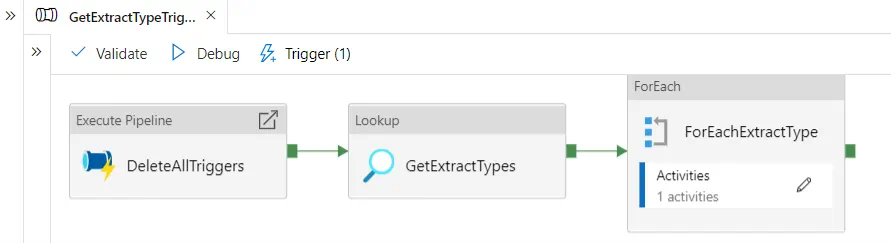
Putting this all together we can create a parent Synapse pipeline called GetExtractTypeTriggers that first calls the DeleteTriggers pipeline and then calls the CreateExtractTypeTriggers pipeline to orchestrate the flow of logic that synchronizes the triggers on the Synapse workspace with the triggers defined in our ScheduleTriggers data lake file that we created earlier.
Create Storage Based Event Trigger
Now that we have our Synapse pipelines created to do the work to delete and create the triggers, and a pipeline to do ELT work that will be defined for our customer, for example, ExtractType code, we need a way to detect when there has been a change by the customer or business in terms of the requirements for when our DoWork ELT needs to be executed.
If we don’t want to have to run each change through a Change Request process, for example, and go through the process of stopping, deleting, and recreating each trigger manually, we can leverage a Synapse pipelines storage-based event trigger to detect changes to the ScheduleTriggers Data Lake file and then execute the GetExtractTypeTriggers pipeline to synchronize the Synapse workspace list of triggers according to the latest definition in ScheduleTriggers data lake file.
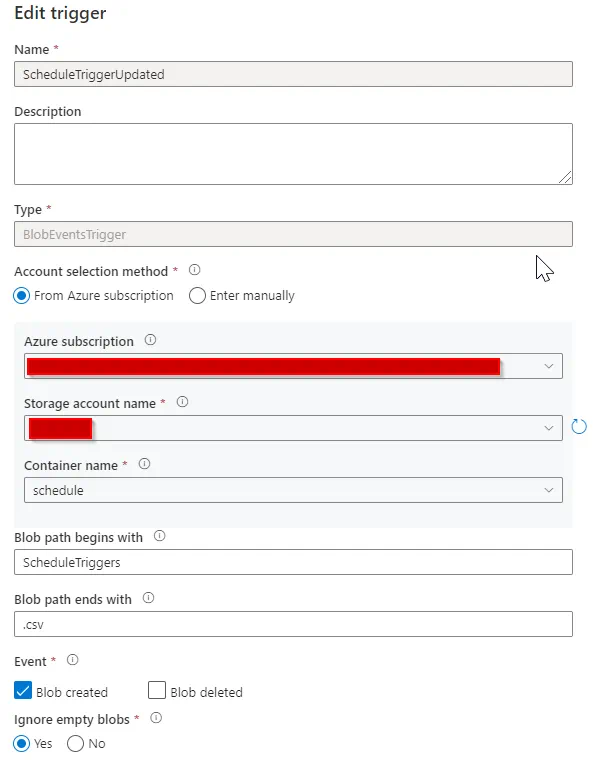
Here we tell the trigger that it must fire upon detecting a chance to the ScheduleTriggers.csv file that is stored on our connected Storage Account Name, for example, our data lake. The trigger must also fire only when it detects a blob-created event that signals a new or overwrites action to the file in the data lake. Once we have created the trigger, we need to attach it to the GetExtractTypeTriggers pipeline.
Demo
Putting this all together we can see in the following illustrations how this works as soon as the ScheduleTriggers.csv file is uploaded to the data lake:
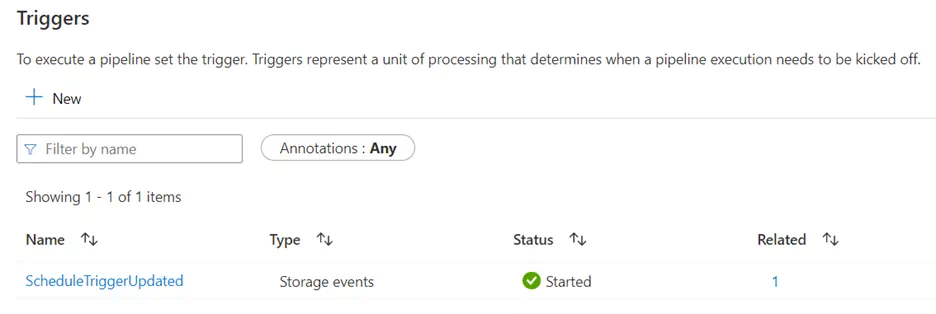

We can now upload the ScheduleTriggers.csv file to the data lake:

The Synapse workspace environment shows that the Storage Based Event Trigger detected the change instantaneously:
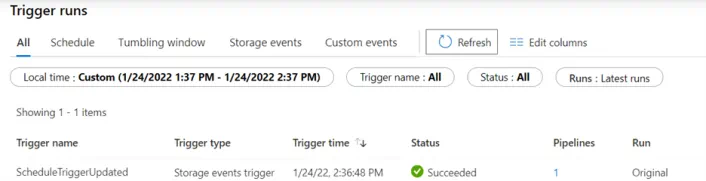
The trigger fired off the GetExtractTypeTriggers Synapse pipeline, which then called the child pipelines to delete and create the triggers according to the data lake file.
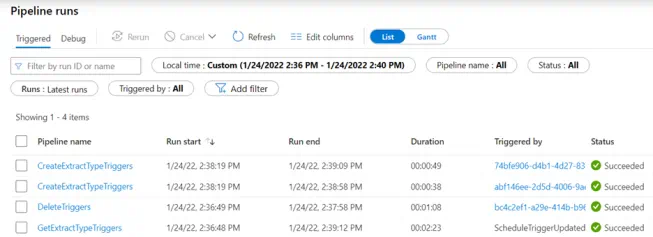
Finally, refresh the webpage, and the Synapse Workspace now has all the triggers created as expected.
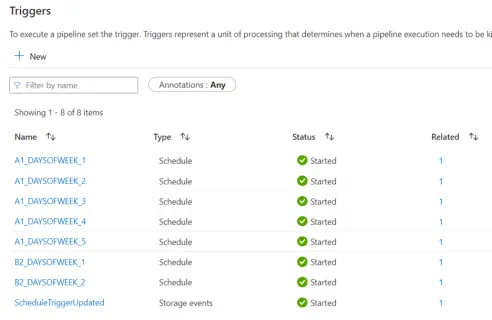
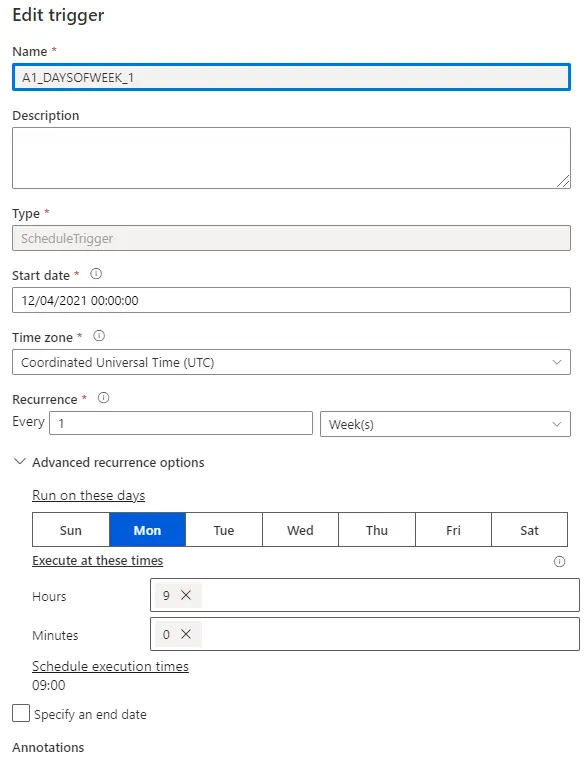
Note: This creates the triggers on the live Synapse workspace, if your workspace is Git-enabled, you will not see the triggers in the Git-enabled workspace view.
Hopefully, this article was a helpful introduction to dynamically creating triggers in Azure Synapse. Hitachi Solutions is proud to partner with Microsoft to deliver solutions using Azure Synapse Analytics. For more information about Synapse or to consult with an expert, contact Hitachi Solutions.