
Always Right or Mostly Right?



Stochastic and Deterministic Systems Engineering
Originally posted on Substack.
Reader, I want to talk about two terms in AI: Stochasticism and Determinism.
Stochastic systems are a bit like rolling dice. You make a likely prediction about what is going to happen, though you may not always arrive at the exact same conclusion. Think weather forecasting models or even a roulette wheel. There’s a bit of an unknown since we don’t really know what is going to happen even when we know all the inputs.
Deterministic systems are fixed and rules-based, like a spreadsheet formula, tax calculation software, or fluid dynamics equations. We know exactly what is going to happen when we know all the inputs.
You may already realize that when you interact with an “AI agent,” you are not getting a fixed, predictable answer! You are actually getting the output of a stochastic system.
Even when you use retrieval augmented generation or RAG!
Understanding the difference between stochastic and deterministic systems is essential if you want to deploy AI (especially agentic AI) responsibly in a business.
How are AI Agents Stochastic?
Ask GPT-5 to do some math and you’ll see the difference between it and a calculator. Sometimes it decides to call the calculator tool built into its toolkit. Other times, it tries to reason through the math itself and gets it wrong. The decision to use the calculator isn’t guaranteed; it’s probabilistic.

This is tool selection variability, one of the most common ways stochasticity shows up in agents. Given the same prompt, an agent might call the “Calculator” tool in one run and skip it in another, even when the calculator was clearly the right tool. For lightweight tasks like summarizing a blog post or searching the web, that unpredictability may not matter much. But in revenue-impacting workflows, or safety-critical ones, the difference between “used the right tool” and “didn’t” can be enormous.
Think of it like cooking: you can throw together a vegetable soup with whatever’s in your fridge, and it will usually turn out fine even if you skip the mushrooms. But a soufflé? That requires precise measurement and timing. Skip a step and the whole thing collapses.
If you need the same outcome, every run, without exception , you don’t want stochasticism. You want determinism.
Why are AI Agents Stochastic?
Agents are typically powered by large language models (LLMs) or similar generative models, which decide their next step by sampling from a probability distribution rather than following fixed rules. LLMs are architected, trained, and called in such a way that creates stochastic results. See my earlier post about other AI systems for an overview.
We call the mathematical model contained with deep neural networks ‘weights.’ Every time you use it, the model will pass your input across the weights within it. These weights come from the model’s learned probabilities during training, which (in state-of-the-art training pipelines) use a little bit of randomness to keep a model from getting trapped in a local optimum. Like rolling a weighted die, the same input may not always yield the same output every time, even if it does most of the time.
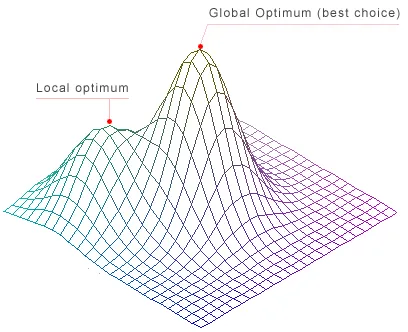
Even if you freeze training randomness (seed everything, use deterministic training), inference for LLMs is stochastic if you sample from the distribution (temperature > 0, nucleus sampling, etc). In any case, the training randomness still affects inference by determining what that distribution looks like in the first place. If you swap out the model at all (if you did not pre-train this yourself and freeze it in place forever), you will be subject to stochasticism. If you change the system prompt at all, you will be subject to stochasticism.
If this section did not make sense to you, please show it to your tech lead. They know what I mean.
When do I Need One or the Other?
Short answer: whenever you need to make a critical decision, you should use deterministic systems, since they are much more reliable and explainable.
Longer answer: many use cases require hybrid systems that combine both deterministic and stochastic subsystems:
- Deterministic core for rules, compliance, and repeatable calculations.
- Stochastic layer for exploration, adaptation, and creativity.
Example:
A marketing optimization engine might use a deterministic set of business rules (“don’t advertise to customers who opted out”) but stochastic generation to create and test different ad variations.
Notice how that stochastic layer does not always need “AI” in the chair. Creativity comes from human beings! We humans are very stochastic already. LLMs can certainly help out too, as they are naturally stochastic systems.
In my humble opinion AI agents do well in three areas:
- Subjective Tasks: for use cases where there is no wrong answer, like generating an image or writing an email from scratch.
- Tasks That Can Tolerate Some Error: info lookups in non-critical systems, brainstorming, social media posts, customer support summaries, documentation drafting, etc.
- Easily Verifiable Tasks: if you, the user can quickly validate the output of the agent, that is probably good use case for agents.
When Agent Output is Hard to Validate
If you can’t reliably validate an agent’s output, that’s a bad use case. I’d put code generation firmly in this category.
It reminds me of my high school calculus class. I had a TI-Nspire, an insanely powerful calculator that could graph, solve, and crunch symbolic equations. It felt like a superpower. But my teacher would always remind me: “Don’t lean too hard on it. You still need to show your work.”
Why? Because if you couldn’t solve the problem yourself, the calculator couldn’t magically do the exam for you. Sure, it could spit out an answer, but unless you understood the steps, you wouldn’t get full credit, and if the output didn’t make sense, you were completely stuck.
That’s the same problem with AI code generation. People treat tools like GitHub Spark or Claude Code as if “vibe coding” is the future of development, until their first build fails. Then they realize they don’t actually have the skills to debug, validate, or make use of what the model gave them.
A calculator doesn’t make you a master mathematician, it just crunches numbers faster. In the same way, an AI code generator doesn’t make you a competent developer. If you can’t validate agent output, you shouldn’t be leaning on the tool for that use case.
Appendix: Whataboutisms
Even if your agent appears deterministic because it’s mostly calling fixed tools or workflows, the planning/reasoning layer is usually stochastic unless explicitly replaced with hard-coded logic. Here are some common criticisms I’ve heard, and why they don’t quite hold up:
My agents don’t generate text, they just call APIs or tools.
- The decision-making about which tool to call, in what order, and with what parameters still comes from a stochastic model unless you’ve hard-coded it.
- Even if tool execution is deterministic, the agent’s plan can vary between runs on the same prompt because the LLM reasoning layer is probabilistic.
I’ve locked the temperature to 0, so it’s deterministic.
- Temperature 0 reduces randomness in token selection but does not guarantee determinism across runs. Subtle differences in prompt formatting, hidden system prompts, or upstream model updates can still yield variation.
- And in multi-step agents, even one tiny stochastic variation early can change the entire plan.
My agent is a workflow engine with a fixed chain of steps.
- That’s not truly “agentic”. It’s closer to an automated script or orchestration pipeline.
- A genuine agent typically has to decide what to do next based on environment state, and the decision layer is almost always stochastic if driven by an LLM.
Deterministic toolchains are more reliable, so stochasticity isn’t relevant to my agent.
- Even in “reliable” agents, the risk from hidden stochastic behavior is that two identical cases might be treated differently without a clear reason, something you must control for in regulated or high-trust domains.
I can unit test my agent, so it’s deterministic.
- The passing rate might be high for the tested cases, but untested edge cases could still show variability. How sure can you really be on this?
- Stochasticity can be masked by narrow testing, but it reappears as soon as you expand coverage.