Beyond the Warehouse: Lakehouses Modernize Data Architecture

")


This is the first article in a four-part blog series where we’ll look at the evolution of data storage and analytical architectures and how they contribute to creating mature, data-driven organizations. Customer maturity along the data spectrum is indeed a journey, and building the appropriate architecture over time is a key component. Join us as we provide insight into what organizations can do now to better prepare for technological changes in the future.
As businesses grow, massive amounts of data are generated every day. Organizations have been struggling with how to manage this data for years — how to set up the most cost-effective architecture so data can drive insights and ultimately, business outcomes. It’s all part of establishing data maturity, the notion of making the best use of all types of data — from proprietary transactional data to social media data to data generated by IoT devices. Is the journey endless? Not necessarily — new architectures are helping us get there rapidly.
But the evolution has been ongoing for decades, starting with the data warehouse in the late 1980s and moving to data lakes in 2010. As business needs change requiring more specific answers to business challenges, digital assets must adapt and shift to meet the growing demand this has led to newer concepts being developed such as data lakehouse, data fabric, and data mesh. The cloud, of course, has and continues to be the foundation for these dynamic shifts. Let’s take a quick look back.
The warehouse comes up short
Data warehousing started with the great promise of helping business leaders gain analytical insights by collecting data from operational databases in centralized warehouses. Warehouse data was schema-based, ensuring that it was optimized for downstream business intelligence. These were called first-generation data analytics platforms.
A decade ago, these first-generation systems started to face many challenges. First, they typically coupled computing and storage on-premises making data analysts miserable. They often had to wait 24 hours or more for data to flow into the warehouse before it was ready for analysis and even longer to run complex queries.
Mergers, acquisitions, and competing internal projects resulted in the creation of multiple data warehouses. As a result, warehouses themselves became pockets of data disparity. The risk of data drift and inconsistencies proliferated and in some cases were nearly impossible to reconcile.
Warehouses were also designed in a way that increased dependency on the proprietary data warehouse vendor to a point where the organization could not access its own data without paying the vendor. Called vendor lock-in, companies couldn’t free themselves, even when there was a new and better technology alternative available in the market.
Because data warehouses solely focus on structured, transaction-based data, the limitations became problematic when companies wanted to start taking advantage of the increasing variety of data (text, IoT, images, audio, videos, drones, etc.) available for analysis. And finally, the rise of machine learning (ML) and artificial intelligence (AI) required direct access to data that was not based on SQL. So, to take advantage of AI or ML, data had to be moved physically out of the warehouse again.
That’s a lot of reasons to look for something better.
Data lakes enter the picture
New demands dictated a new approach. Terms like big data, cloud computing, data lakes, analytics and self-service became commonplace. These second-generation platforms were designed to capture all data by offloading it into data lakes.
Data lakes are simply repositories for data and store that data in its natural/raw format. Let’s look specifically at what is being dumped:
- Structured data from relational or transactional databases (rows and columns)
- Semi-structured data (CSV, logs, XML, JSON)
- Unstructured data (emails, documents, PDFs)
- Binary data (images, audio, video)
A data lake works on a principle called schema-on-read. This means there is no predefined schema into which data needs to be fitted before storage. Only when the data is read during processing is it transformed into a schema. This enables the agile storing of data at a low cost, but punted the problem of data quality and governance downstream.
For BI analysis, a small subset of data is later moved to a downstream warehouse. The use of open formats did make data lakes data directly accessible to a wide range of other analytics engines, such as ML systems.
But not all was rosy. Data lakes can be highly complex architectures for those who must work with and manage them. Data becomes scattered in multiple repositories, file shares, storage accounts, or databases, resulting in difficulty to locate and combine, and leading to the creation and maintenance of complicated pipelines and data joins. Data is copied multiple times in the process, taking up excess storage space and raising data governance and security concerns.
Keeping the data lake and warehouse consistent is difficult when data in the warehouse becomes stale compared to data in the data lake. You end up with what’s commonly known as a data swamp, and it gets murkier because companies store unnecessary and outdated data and don’t manage for consistency and relevance. These overlaps and inconsistencies between data lakes and data warehouses suggest the data lake has become yet another data silo.
Business analysts became frustrated by the lack of direct access to data, slow turnaround, and reporting limitations. And data architects struggled to catalog and manage access rights as redundant copies of data proliferated. Moreover, many enterprises want to use advanced analytics such as ML and AI, and neither data lakes nor warehouses are ideal for that.
Is the lakehouse the answer?
From the swamp, there emerged a new class of data architecture called the data lakehouse. Lakehouses can store, refine, analyze, and access all types of data needed for many new data applications — structured, semi-structured, or unstructured. Data is stored in open formats that allow standardized APIs via many different tools to read and write and access it directly and efficiently.
____________________________________________________________________________________
Traditional data warehouses use crafted schemas designed to answer predetermined queries quickly and efficiently. Data lakes store all your data, but historically they can be harder to query because data is not rigorously structured and formatted for analysis. A data lakehouse combines the best of both.
____________________________________________________________________________________
This lakehouse architecture, referred to as third-generation data architecture, has several components:
- Data from the structured environment
- Data from the textual environment
- Data from the analog/IoT environment
- An analytical infrastructure allowing data in the lakehouse to be read and understood
The analytical infrastructure allowing data to be read and transformed while it’s in the lake is the leap forward. It can be achieved because the environment and data format are open. What exactly does that mean?
It means cloud services can access the data directly instead of going through a data warehouse vendor’s proprietary format or moving/copying the data from the data warehouse for access. It gives you the flexibility to use multiple best-of-breed services and engines on your company’s data or whatever else you want to process the data. Companies have lots of use cases and needs, so being able to use the “best tool for the job” really means higher productivity.
Because a lakehouse writes the data once in this open format, it can be read many times without the need for exporting and duplicating. Another change in pattern is the traditional Extract-Transform-Load (ETL) model of data warehousing has now changed to Extract-Load-Transform (ELT). In the traditional ETL model, analysts are accustomed to waiting for the data to be transformed first since they don’t have direct access to all data sources. In a modern data lakehouse, massive amounts of data can be transformed anytime without the need to wait for data engineers or database admins to serve the data — and this can be accomplished in real-time.
This simple architectural diagram illustrates it well:
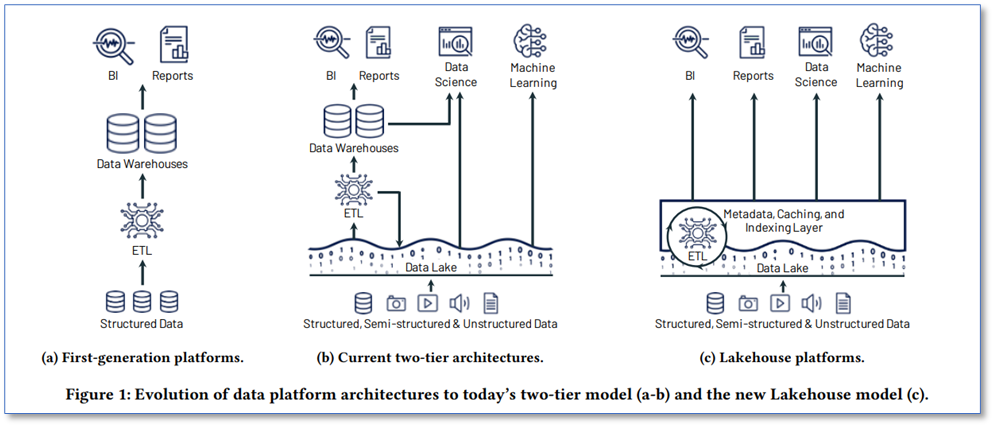
Source: Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
Lakehouses combine the key benefits of data lakes and data warehouses: low-cost storage in an open format accessible by a variety of systems from the former, and powerful management and optimization features from the latter. The key question is whether organizations can combine these benefits in an effective way.
Here’s how it all shakes out:
| Data Warehouse | Data Lake | Data Lakehouse | |
|---|---|---|---|
| Format | Closed, proprietary formats | Open format | Open format |
| Data Types | Structured, transactional data/limited support for semi-structured | All types: Structured, semi-structured, and unstructured (raw) | All types: Structured, semi-structured, and unstructured (raw) |
| Data Access | SQL only — no direct file access | Open APIS for direct access to files using multiple programming languages | Open APIS for direct access to files using multiple programming languages |
| Data Quality/Reliability | High quality and reliability with ACID transactions | Low quality, data swamp | High quality and reliability with ACID transactions |
| Governance and Security | Fine-grained security and governance for row and column-level tables | Poor governance because security needs to be applied to files | Fine-grained security and governance for row and column-level tables |
| Performance | High | Low | High |
| Scalability | Exponentially more expensive | Scales to hold any amount or type of data | Scales to hold any amount or type of data |
Modern data architectures increase business value
Modernizing data architecture allows businesses to realize the full value of their unique data assets, opens real-time options for AI-based data engineering, and can further unlock the value of legacy data.
Modern architectures handle all sources, formats, and types of data way beyond the carefully structured data of business transactional systems. While structured data is some of the most important data in a business, it is no longer the only important data. The data that’s available today can be analyzed and used to truly drive business outcomes, but you need:
- The right infrastructure for scaling
- Real-time discovery
- Integrated AI and ML
- Open environments that are easily adaptable
A “one size fits all” approach leads to compromise and a solution that isn’t optimized for anyone. With modern data architecture, customers can integrate a data lake, data warehouses, and purpose-built data products and services, with a unified governance layer, to create a highly usable system to drive analytics.
Putting it together
To recap, data warehouses have solved data problems for a long time, but they fail to fulfill the diverse requirements of modern use cases and workloads. Data lakes were built to alleviate some of those limitations; however, they still lacked openness and created data swamps. Lakehouses are the next generation of data solutions, which aim to provide the best features of databases and data lakes and meet all the requirements of diverse use cases and workloads.
Ultimately, the goal is to operationalize business intelligence, providing business analysts and data scientists with fast access to any data type with a variety of computing tools and platforms.
It’s a lot to consider. Don’t be afraid to call for reinforcements. The real value of big data depends on its ease of use as much as its potential outcomes. If you are just starting your data lake journey, or you are currently mired in a swampy lake, a dedicated partner to help guide you in choosing the right solution can help.
Here at Hitachi Solutions, we’ve built an entire business unit dedicated to helping organizations derive valuable insights from big data. From data and analytics services to a dedicated data science team, we offer a vast library of resources and enterprise analytics expertise.
If you are considering modernizing your legacy data platform to one that leverages native Azure services, consider our offer. Our data solutions experts will work with you to identify your current data estate, define the future state, and determine the best path forward for your organization.
Stay tuned for the next installment of this blog series! And if you have any questions about this post or Hitachi Solutions’ data offerings, please contact our team. We would be happy to help.