
A Comprehensive Guide to Direct Lake Semantic Model Migration for Power BI



Earlier this year, Microsoft announced an innovative semantic model storage mode for Power BI called Direct Lake. It fundamentally changes how we create and consume BI solutions. The new approach aims to provide a perfect balance between the existing import mode and DirectQuery (DQ) mode.
While the import mode is fast, you do not get the latest data. On the other hand, in the DQ mode, you get the latest data from the source but the query performance suffers. In Direct Lake mode — exclusively available in Fabric — the queries are sent directly to the Delta tables in the Fabric OneLake, thus returning the latest data at import-like performance.
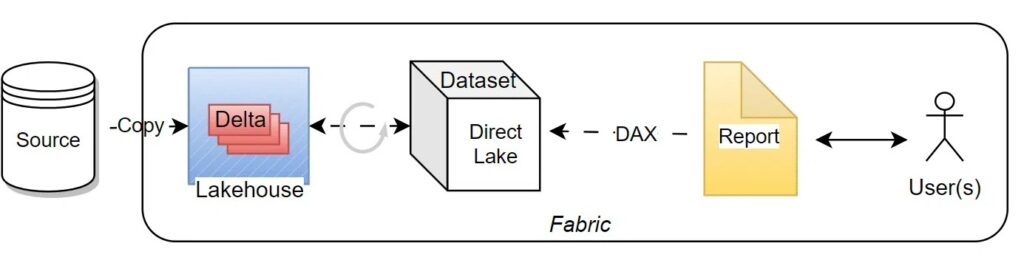
The key here is “Delta table.” Instead of the proprietary format, Direct Lake uses the open-source Delta format from the Lakehouse. Currently, the semantic model has to be prepared using the Fabric compute engines for the best performance. This changes the way the models are created and maintained compared to the import or DQ models.
In this blog post, we will highlight the differences so you can prepare to migrate the existing semantic models to Direct Lake, if appropriate.

Prerequisites
As of November 15, 2023, the prerequisites to create and use Direct Lake datasets are:
- Microsoft Fabric or Premium capacity
- Delta table in Fabric Lakehouse or Warehouse
- SQL endpoint to the Lakehouse or the Warehouse
- XMLA Read/Write enabled in Power BI capacity settings
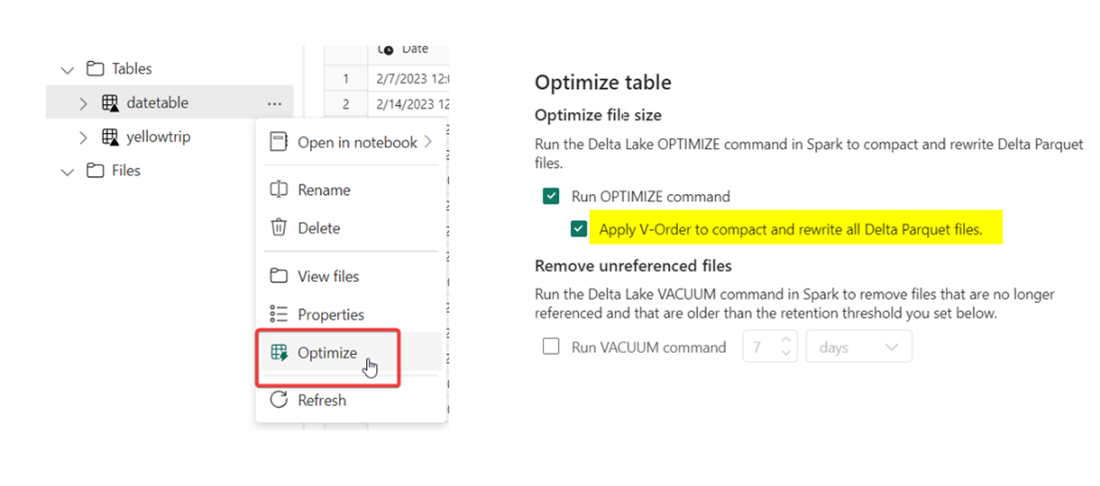
- Although it’s not a requirement, the Delta table should be V-Order optimized for optimal performance
- Tabular Editor 2 or 3, 3 preferred
Migration Checklist
Data Transformation
- As mentioned above, Direct Lake uses the Delta table stored in the Fabric Lakehouse or the Warehouse. Thus, any existing Power Query transformation steps created in the semantic model must be replicated in the Lakehouse/Warehouse using Spark, Dataflow Gen2, or T-SQL in the Warehouse. If you are not familiar with Spark or T-SQL, Dataflow Gen2 will be the easiest way to use the existing M transformations. You can connect to the data source using connectors available in Dataflow Gen2, use the existing M code and save the resulting table to OneLake as a Delta table destination.
- Unlike the import and DQ modes, Direct Lake does not have referenced queries or parameters. You will need to apply transformations in the Lakehouse/Warehouse to account for those.
- Although the Delta table can be partitioned (highly recommended), Direct Lake semantic model has only one partition irrespective of the number of partitions in the Delta table. If you have an existing import semantic model with multiple partitions, you will need to partition the Delta table accordingly. Currently, Dataflow Gen2 does not directly allow the creation of partitions and will have to be created using Spark.
- Calculated columns and tables should be created in the Lakehouse/Warehouse using Python/Spark/T-SQL.
- Be sure to use the same datatype as your import/DQ semantic model. Please note that not all data types are supported yet. The semantic model data type must match the data type in the Lakehouse/Warehouse. Please check the official documentation for limitations and guidance.
- As of the writing of this blog, column mapping in Delta tables is not supported. Thus, table and column names cannot have special characters such as spaces. When creating a Power BI semantic model, it’s always best practice to use business friendly names. For example, instead of CustomerName, the semantic model should have “Customer Name.” Once you have created the Delta table, you should change the table and column names to match the import/DQ models using Tabular Editor (TE). We recommend using underscore (for example customer_name) in the Delta table so all the column and table names can be renamed programmatically using C# in TE. The below script can be used in TE for that.
- If you have defined an incremental refresh policy in the semantic model, you will need to replicate that in your ETL pipeline. Direct Lake does not currently have incremental refresh. Alex Powers has a blog on how you can achieve incremental load using Fabric pipelines and Dataflow Gen 2.
- If you are using any Power Query functions, you will need to incorporate it in the transformation logic in the Lakehouse/Warehouse.
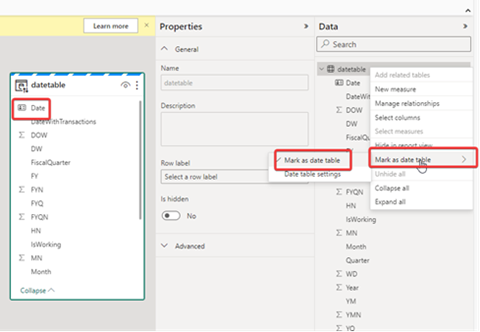
- If you are using Auto Datetime, create a date dimension table instead (which is the recommended practice as well). Direct Lake does not have Auto Datetime. Create a date table and mark it as Date Table either using the web modeling or in TE.
- For best Direct Lake performance, it is recommended to create Delta tables that are V-Order optimized.
- At MS Ignite Microsoft announced that Direct Lake will support RLS using stored credentials. Users will be able to define RLS in the Web editor as well as in Tabular Editor. As of writing this blog, it was still being rolled out. Direct Lake will fallback to DQ if the RLS/OLS are defined in the data warehouse to ensure security is enforced. Refer to the official documentation for details.
/*
Replaces "_" in all column and table names with space and converts to Title Case.
Always backup before running the script.
example: customer_name to Customer Name
*/
foreach (var table in Model.Tables)
{
// Replace underscores with spaces and convert to title case for table names
string newTableName = table.Name.Replace("_", " ");
newTableName = System.Threading.Thread.CurrentThread.CurrentCulture.TextInfo.ToTitleCase(newTableName.ToLower());
table.Name = newTableName;
// Loop through all columns in the table
foreach (var column in table.Columns)
{
// Replace underscores with spaces and convert to title case for column names
string newColumnName = column.Name.Replace("_", " ");
newColumnName = System.Threading.Thread.CurrentThread.CurrentCulture.TextInfo.ToTitleCase(newColumnName.ToLower());
column.Name = newColumnName;
}
}
```

Measures
- If the table names and column names between Import/DQ and Direct Lake models match, all measures should work fine. To migrate the measures from your existing model to Direct Lake, you can export the measures along with the measure properties (description, annotations, formatting etc.) and import them into the newly created Direct Lake dataset using TE and XMLA endpoint. You can use the below script to achieve that:
```
// Export All Measures as a .tsv file to the specified location
var path = @"C:\\MProp.tsv";
var props = ExportProperties(Model.AllMeasures,"Name, Description, Expression, Table, DisplayFolder, FormatString, IsHidden, DataType");
SaveFile(path, props);
```
After exporting, use the below script to import the same measures into the Direct Lake model using TE:
```
// Imports the measures with properties. If a measure with the same name is found, properties/DAX are updated.
var path = @"C:\\MProp.tsv";
var measureMetadata = ReadFile(path);
var tsvRows = measureMetadata.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
// Loop through all rows but skip the first one:
foreach (var row in tsvRows.Skip(1))
{
var tsvColumns = row.Split('\t'); // Assume file uses tabs as column separator
var name = tsvColumns[1]; // 1st column contains measure name
var description = tsvColumns[2]; // 2nd column contains measure description
var expression = tsvColumns[3]; // 3rd column contains measure expression
var tableParts = tsvColumns[4].Split('.');
var table = tableParts.Length > 1 ? string.Join(".", tableParts.Skip(1)) : null;
// If the table name is null, skip this measure
if (table == null)
{
continue; // Skip the current iteration
}
var folder = tsvColumns[5]; // Folder Name
var format = tsvColumns[6]; // Format string
// Find the table and measure if it exists
var measure = Model.Tables[table].Measures.FirstOrDefault(m => m.Name == name);
// If measure with the same name exists, update its properties
if (measure != null)
{
measure.Description = description;
measure.Expression = expression;
measure.DisplayFolder = folder;
measure.FormatString = format;
}
else
{
// If measure with the same name does not exist, add it
measure = Model.Tables[table].AddMeasure(name);
measure.Description = description;
measure.Expression = expression;
measure.DisplayFolder = folder;
measure.FormatString = format;
}
}
ImportProperties(measureMetadata);
```
- Note that since Direct Lake does not have calculated tables, field parameters aren’t supported. You will need to create either disconnected tables or calculation groups. Calculation groups are supported in Direct Lake.
- In general, it is best practice to only filter required columns in DAX measures instead of ALL(Table) to prevent caching the entire table. This becomes even more important with Direct Lake as Direct Lake loads only queried columns.
- Direct Lake has fallback mechanism in which the query can switch to DQ under certain scenarios. If the semantic model size exceeds the limits per SKU or uses features not supported by Direct Lake (views in WH, RLS/OLS in WH etc.), the “query” will be in the DQ mode. It is important to note here that while the storage mode partition will still show “Direct Lake”, it’s the query that will be in DQ in those cases. You can check if the query is in Direct Lake or DQ, by using DAX Studio, SQL Server Profiler or Performance Analyzer in Power BI Desktop. This fallback mechanism can be restricted by changing DirectLakeBehaviour property in TOM or using Tabular Editor. It is highly recommended to test the queries, especially for large model sizes. Refer to official documentation for guidelines and limits : https://learn.microsoft.com/en-us/power-bi/enterprise/directlake-overview#fallback
- We highly recommend creating a measure table instead of saving the measures in the fact table. Currently, if a table has measures, it cannot be dropped easily. If you create measures in a separate table, you will be able to drop or alter tables in case of schema changes.
- As mentioned above, if any measures rely on an auto date-time table for time intelligence, be sure to update them to use the date dimension table.
- It is possible that the query plan generated for Direct Lake may be different from import even though the DAX expression is the same. It is important that you use DAX studio to analyze the query plan and trace server timings to understand the differences to ensure optimal performance.

Relationships
- The best practices for creating the semantic model (star schema, etc.) also apply to Direct Lake.
- Unlike Import/DQ, a valid relationship can only exist between two identical column types.
- In your ETL pipeline ensure that the primary keys contain unique values.
- DateTime columns cannot be used in a relationship at this time. You can convert it to date or use integer key to define relationship.
- Dual or composite models are not yet supported so you must create/shortcut the Delta table to use it in the Direct Lake model.

Deployment
- Use the Git integration to develop the Direct Lake model.
- Setup either auto-refresh or scheduled refresh for the dataset. If you select the first option, any changes to the Delta table are automatically detected and the Direct Lake tables are updated. This allows DQ like latency so the report connected to the dataset always shows the latest data. If the underlying Delta tables change infrequently, or if you want to follow the same refresh schedule as the import dataset, turn off auto-update and set the schedule manually
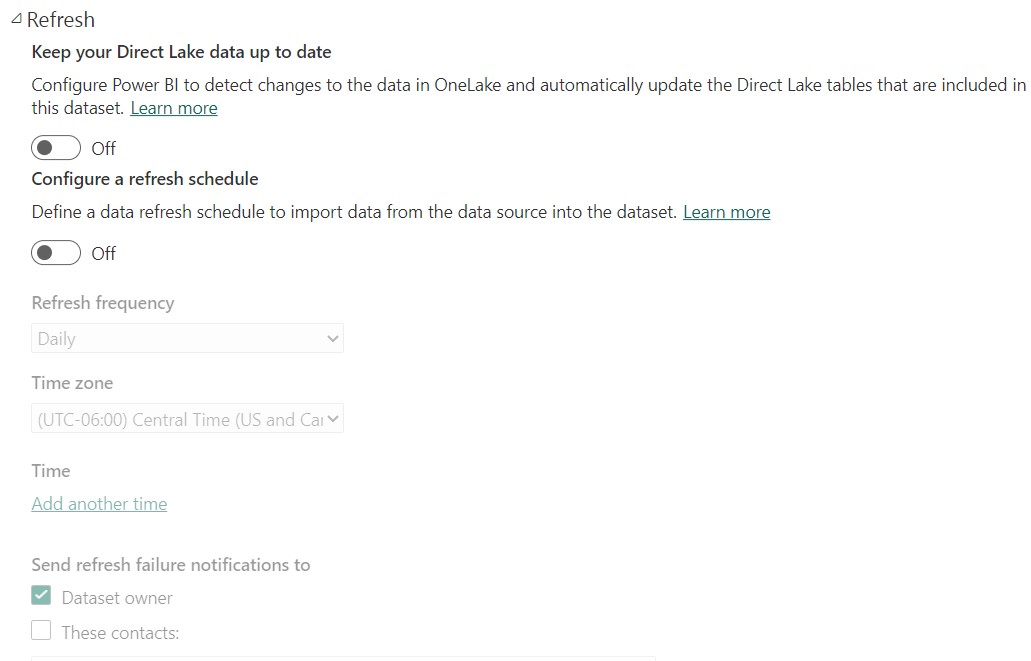
- If the model is updated using XMLA endpoint in the external tools, the Web modeling view cannot be used.
- Note that if you are using a Pay-As-You-Go Fabric license, if the capacity is paused, Direct Lake will not work.

Ready to Learn More?
As Microsoft Fabric reaches general availability, now is the time to explore its potential impact on your organization’s data consolidation and unification efforts. Hitachi Solutions has been closely involved with Fabric’s development for two years, providing testing and feedback to the Microsoft Fabric product team. This helped them refine and enhance the platform, while upleveling our team and positioning us as a top Fabric partner.
Hitachi Solutions is a leading global systems integrator who specializes in Microsoft technologies. Powered by nearly two decades of experience, we deliver end-to-end business transformation through advisory services, industry and technology expertise, and implementation excellence. Our goal is to support and accelerate data and business modernization initiatives that drive value for customers. Contact us to learn more or speak to one of our experts!