
Operationalizing Machine Learning Pipelines in Fabric



What is MLOps?
MLOps is the whole system of operationalizing your machine learning models. While the idea is conceptually simple, the process of deploying and maintaining machine learning models consistently and reliably is difficult.
Data scientists by training tend to focus on the first two phases of MLOps: design and model development. However, it’s that final stage, operations, that takes all the research that has been done to find a useful model and turns it into an actionable business tool.
According to Hitachi Solutions Data Science Vice President Fred Heller, “This is where we take a predictive model and turn it into money.” The Hitachi Solutions data science team has many years of experience implementing MLOps pipelines, and we are here to help.
In this blog, we specifically focus on a framework developed for consistent and reliable model deployments, and we show you how to do that in Microsoft Fabric.
Model Deployment Foundation
Here’s the scenario. You worked with your key stakeholders to find a brilliant solution to a costly business problem. You developed useful modeling features, created a model, and — through testing and validation — proved it will provide loads of value to your organization. Great! Now what?
You need to deploy this thing to your production workspace in Fabric, so it can score new data as it arrives. Likely, you might even have a staging, test, or UAT workspace you want to push this to for full integration testing with your other applications. After all, you don’t want your new model to crash your critical operational systems.
So, let’s assume you developed your model in a dev workspace in Fabric, and you want to deploy it to a staging or prod workspace. It’s critical that these workspaces are set up as consistently as possible. For that reason, we encourage you to include as much of the workspace setup as possible in your notebooks.
What Needs To Be Set Up in Fabric?
At Hitachi Solutions, we define one or two essential parameters that can then derive the other parameters needed to build the entire foundation required for the modeling lifecycle. Based on these essential parameters, we can orchestrate the following:
- Define parameters for all objects referenced throughout the project notebooks
- Build Delta tables for raw and transformed data, modeling features, scoring features, and scored records
- Create the MLflow experiment
- Create the MLflow model registry
- Create jobs/pipelines for retraining models and scoring new data
The only dependencies are:
- All project notebooks are copied into the new workspace
- The lakehouse is created in the new workspace
All that needs to be done from there is run these key build commands and — ta-da — your Fabric workspace is set up for business! Let’s take a deeper look at how we do that.
How Do We Do it?
Define Parameters in Fabric
We determined a way to make all other parameters in our Fabric project derived from two key required parameters: lakehouse and model_registry_name. These two parameters are defined here.

Make sure the notebook cell is set to require these parameters by selecting the ellipse (…) and select “Toggle parameter cell.” This makes the “Parameters” indicator appear at the bottom of the cell, thus enabling the parameters to receive new values if the notebook is called from somewhere else in your Fabric workspace.
From there, we recommend deriving names of any other objects using f-strings. Note that we recommend the experiment name is the same as the model registry name.

Build Delta Tables in Fabric
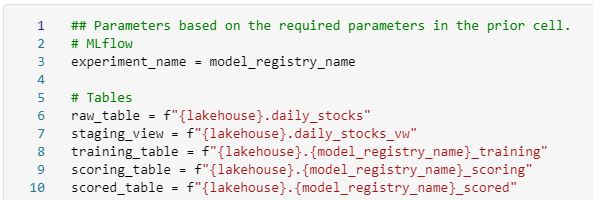
You can now pass the table names to a notebook that creates the tables in the lakehouse. We do this through the use of the Microsoft Spark Utilities.
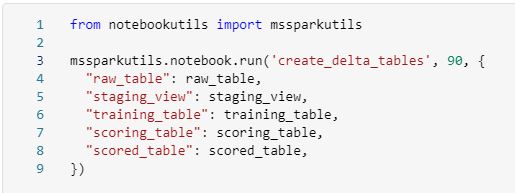

Again, make sure that the “create_delta_tables” notebook is set to receive these parameters.
Then create each table using the spark.sql() method that references the table name passed in via parameter. See an example of this type of table creation we would include in the “create_delta_tables” notebook.

Create MLflow Experiment in Fabric
Why do you need an experiment in Fabric? Every time you create a model, you may want to collect certain validation metrics. Especially when performing parameter tuning, you may want to also capture the exact parameters that created that model run.
Experiments are the one place where you log anything your heart desires about every model run created. You can capture the pickle file to recreate the output, an input sample, the runtime and library configurations, and even diagrams.
The experiment provides full transparency and traceability over all of the model runs you have created in your Fabric project, as well as the ability to download all of those artifacts for future use. This way, you can always reproduce an output and you can also compare outputs for all models very efficiently.
Pass the “experiment_name” and “model_registry_name” into the “mlflow_setup” notebook and ensure that the “mlflow_setup” notebook is set up to receive those parameters.
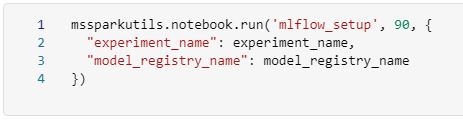

Create the experiment if it does not already exist using the MLflow library methods. Note that if you have to deploy updates, you do not want to wipe out or override your experiment history.
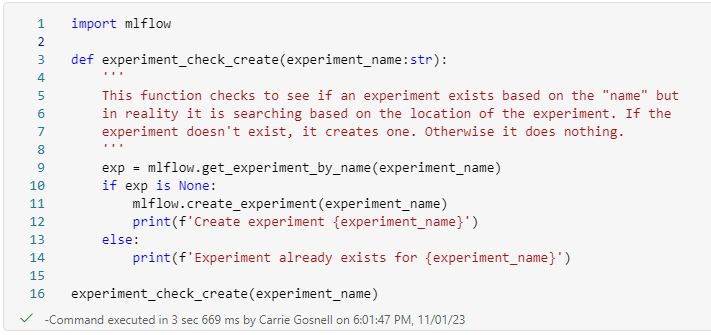
Create MLflow Model Registry in Fabric
What is the purpose of the model registry in Fabric? It serves as a model store, with a set of APIs for calling the model and a UI to manage the model lifecycle. It also provides full lineage back to the experiment run that was used to create the model and version control as your model changes over time. In short, this is what serves your model in Fabric out to the rest of your systems that you might want to integrate the model results with.
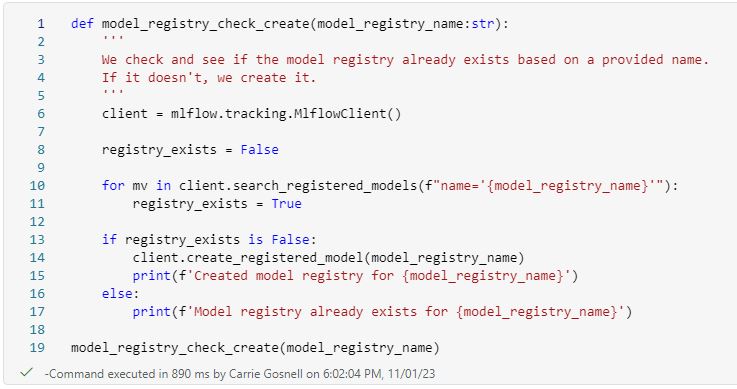
Create the model registry if it does not already exist using the MlflowClient library methods. Again, we do not want to wipe out history in the case of updating a model when deploying model updates.
Create the model registry if it does not already exist using the MlflowClient library methods. Again, we do not want to wipe out history in the case of updating a model when deploying model updates.
Ready to Roll…
Now you have parameters to pass to any other notebooks in your Fabric project that perform ETLs, model training, model promotion, and new data scoring to indicate which objects to interact with. Most importantly, MLflow is set up to log experiment runs to register your best run as a model, and to promote your model for production use on new data.
More To Come!
Of course, it isn’t that easy. There are many other steps to maintain your models in Fabric, and we will dive into each piece over time.
This blog is the first in a series that will demonstrate how to do MLOps in Fabric. In our next blog, we will discuss how to interact with the new features announced at the 2023 Ignite Conference. For now, the steps in this blog will create the foundation you need to operate.
Kickstart Your Analytics Initiatives with Hitachi Solutions
As Microsoft Fabric reaches general availability, now is the time to explore its potential impact on your organization’s data consolidation and unification efforts. Hitachi Solutions has been closely involved with Fabric’s development for two years, providing testing and feedback to the Microsoft Fabric product team. This helped them refine and enhance the platform, while upleveling our team and positioning us as a top Fabric partner.
Hitachi Solutions is a leading global systems integrator who specializes in Microsoft technologies. Powered by nearly two decades of experience, we deliver end-to-end business transformation through advisory services, industry and technology expertise, and implementation excellence. Our goal is to support and accelerate data and business modernization initiatives that drive value for customers.